The recommendations and suggestions below represents real life experience and excerpts from the Microsoft Technet article : http://technet.microsoft.c
SSIS (SQL SERVER INTEGRATION SERVICES) is using a buffer-oriented architecture to efficiently load and manipulate datasets in memory, the benefits is avoiding the I/O to the disk and physically copying the data to the disk, and therefore it’s transferring the data from the source to the destination through the pipeline without touching the disk.
As this data flows through the pipeline, SSIS attempts to reuse data from prior buffers as much as possible when additional operations are performed. How buffers are used and reused depend on the type of transformations that you use in a pipeline.
There’re 3 types of transformations types:
1-Row Transformation (synchronous transformation) also known as (Non-blocking transformations):
These process the data in Row-by-row basis, Row transformations have the advantage of reusing existing buffers and do not require data to be copied to a new buffer to complete the transformation.
• Do not block data flow in the pipeline.
• Data is not copied around, only pointers.
Examples:
• Audit
• Cache Transform
• Character Map
• Conditional Split
• Copy Column
• Data Conversion
• Derived Column
• Export Column
• Import Column
• Lookup
• Multicast
• OLE DB Command
• Percentage Sampling
• Script Component
• Slowly Changing Dimension
2-Partially Blocking Transformation (asynchronous transformation):
Are often used to combine several datasets. They tend to have multiple data inputs. As a result, their output may have the same, greater, or fewer records than the total number of input records.
• Introduces new buffers in memory layout.
• Transformed data is copied into new buffers.
Examples:
• Data Mining
• Merge
• Merge Join
• Pivot
• Unpivot
• Term Lookup
3-Blocking Transformation (asynchronous transformation):
Blocking transformations must read and process all input records before creating any output records. Of all of the transformation types, these transformations perform the most work and can have the greatest impact on available resources.
• Must see all data before passing on rows.
• Blocks the data flow – can be heavy on memory
• May also use “private buffers” to assist with transforming data.
Examples:
• Aggregate
• Fuzzy grouping
• Fuzzy lookup
• Row Sampling
• Sort
• Term Extraction
Evaluating the performance:
1-You could monitor and observe the performance using the PROGRESS tab, while running the package, it’ll tell you when the task started, ended and how long it’s taking to finish, which would be a great way of discovering which tasks is pulling the performance down.

2-You could also use a free add-on for BIDS (Business Intelligence Development Studio) called BIDS HELPER, can be downloaded from http://bidshelper.codeple
It offers whole new features for the BIDS environment which would help you such as deploying your packages, dtsConfig file formatting and SSIS performance Visualization which I’ll cover now.
Using the SSIS performance Visualization is simple, you just right click on your package after installing the BIDS HELPER and you’ll have new options, you need to select “Execute and Visualize Performance”.

You’ll be introduced to another screen with Performance Tabs, and you choose to visualize the performance by looking at Gantt Bars, Statistics Grid or Statistics Trend, which compares the performance from one execution to another. It adds a new column for each execution and highlights whether the duration of that piece of the package was faster or slower than before.
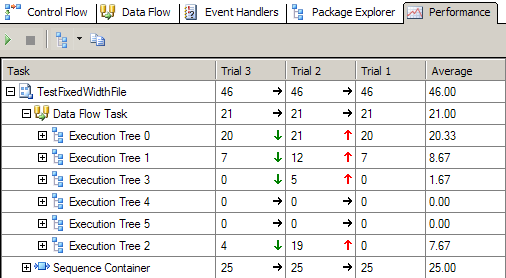
3-Using Perfmon (formerly known as Windows Performance Monitor and synonymously referred to as Perfmon)
There're several counters to monitor SSIS performance, such :
SQLServer:SSIS Service:
SSIS Package Instances - Total number of simultaneous SSIS Packages running
SQLServer:SSIS Pipeline:
BLOB bytes read - Total bytes read from binary large objects during the monitoring period.
BLOB bytes written - Total bytes written to binary large objects during the monitoring period.
BLOB files in use - Number of binary large objects files used during the data flow task during the monitoring period.
Buffer memory - The amount of physical or virtual memory used by the data flow task during the monitoring period.
Buffers in use - The number of buffers in use during the data flow task during the monitoring period.
Buffers spooled - The number of buffers written to disk during the data flow task during the monitoring period.
Flat buffer memory - The total number of blocks of memory in use by the data flow task during the monitoring period.
Flat buffers in use - The number of blocks of memory in use by the data flow task at a point in time.
Private buffer memory - The total amount of physical or virtual memory used by data transformation tasks in the data flow engine during the monitoring period.
Private buffers in use - The number of blocks of memory in use by the transformations in the data flow task at a point in time.
Rows read - Total number of input rows in use by the data flow task at a point in time.
Rows written - Total number of output rows in use by the data flow task at a point in time.
But basically you need to monitor the 3 famous kinds of memory buffers:
"Buffers"
"Private Buffers"
"Flat Buffers"
Read More....
Evaluating Design and performance considerations:
As I always say, everything is life could be done in many different ways; it’s just YOU who needs to decide which approach is better for you as it really depends on your environment and business requirements.
I’m going to point some points that you’ll need to do more research and also included some links so you can look it up in more depth.
1-Remember is that synchronous components reuse buffers and therefore are generally faster than asynchronous components, that needs a new buffer.
2-Break complex ETL tasks into logically distinct smaller packages. More...
3-Maximize Parallelism. Utilizes the available resources as much as you can. More ...
4-Maximum insert commit size and Rows per batch has a great effect for not treating the whole incoming rows as one patch.
5-Minimize staging as possible otherwise use RawFiles. More ...
6- Eliminate redundant columns:
• Use SELECT statements as opposed to selecting the tables dropdown.
• Be Picky! Select only what columns you need VS SELECT *
7-Minimize blocking as much as you can:
• Sort your query in the engine, or even using the SQL command in OLE DB Source instead of using Sort transformation.
• Merge transform requires Sort but not Union All, so use Union All wherever you can. More ...
8- Optimize the BufferTempStoragePath and BLOBTempStoragePath wisely. More ...
9-For Flat File Source use FAST PARSE option for columns of integer and date data types. More ...
10- If the SQL server is local, consider using SQL Server destination instead of OLE DB Destination.
11-Consider indexes fragmentation and performance when inserting high volume of data.
12-Use “Fast Load” when using OLEDB, it uses BULK INSERT and would be faster.
13-Optimize the packet size in your connection managers to 32K (32767) and that’s the fastest option.
More resources on the subject:
Top 10 SQL Server Integration Services Best Practices
Designing and Tuning for Performance your SSIS packages in the Enterprise (SQL Video Series)
Integration Services: Performance Tuning Techniques
That's it...I hope my article helps someone gaining more performance from their ETL solution, and feel free to add more performance considerations






